What is Apriori?
Apriori is an algorithm for frequent itemset mining and association rule learning. It proceeds by identifying the frequent individual items in the dataset and extending them to larger and larger itemsets as long as those itemsets appear frequently enough in the dataset.
The Apriori algorithm has three parts:
- Support
It is very similar to Bayes.
Let’s assume that we are doing a movie recommendation.
- Confidence
Confidence is defined as the number of people who have seen both M1 and M2 movies divided by the number of people who have seen M1.
- Lift
The order of progression of apriori
- Step 1.
Set minimum support and confidence thresholds. - Step 2.
Take all subsets in transactions with support higher than the minimum support threshold. - Step 3.
Take all the rules of these subsets with confidence higher than the minimum confidence threshold. - Step 4.
Sort the rules by decreasing lift values.
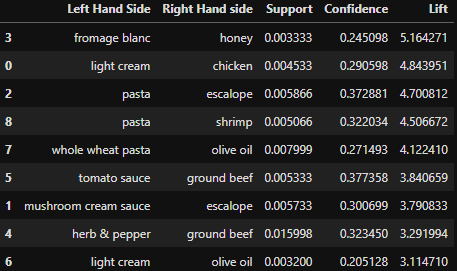
Example
Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from apyori import apriori
rules = apriori(
transactions=transactions,
min_support=0.003,
min_confidence=0.2,
min_lift=3,
min_length=2,
max_length=2)
results = list(rules)
def inspect(results):
lhs = [tuple(result[2][0][0])[0] for result in results]
rhs = [tuple(result[2][0][1])[0] for result in results]
supports = [result[1] for result in results]
confidences = [result[2][0][2] for result in results]
lifts = [result[2][0][3] for result in results]
return list(zip(lhs, rhs, supports, confidences, lifts))
resultsinDataFrame = pd.DataFrame(inspect(results), columns = [
'Left Hand Side',
'Right Hand Side',
'Support',
'Confidence',
'Lift'])
resultsinDataFrame = resultsinDataFrame.nlargest(n=10, columns='Lift')
Result