What are GANs(Generative adversarial Networks)?
GANs generate new images that have never existed before. GANs are formed of two competing networks known as the generator and discriminator.
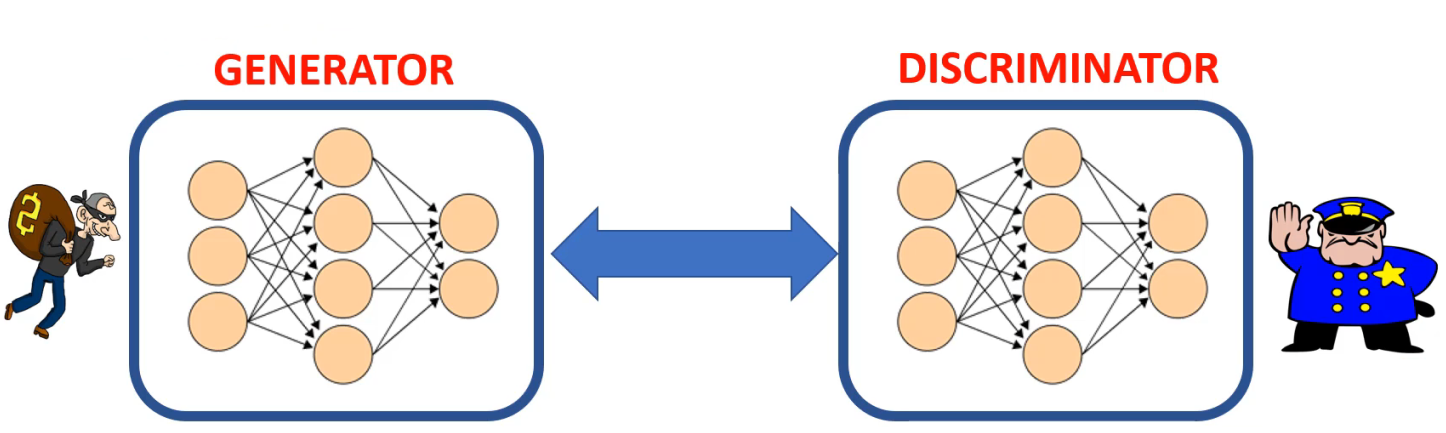
The generator and discriminator learn together through feedback from the discriminator to the generator. “The generator gets better and better at faking images. Eventually, the discriminator will not be able to distinguish between real and fake images.At that point, we can deploy the generator to generate new images.
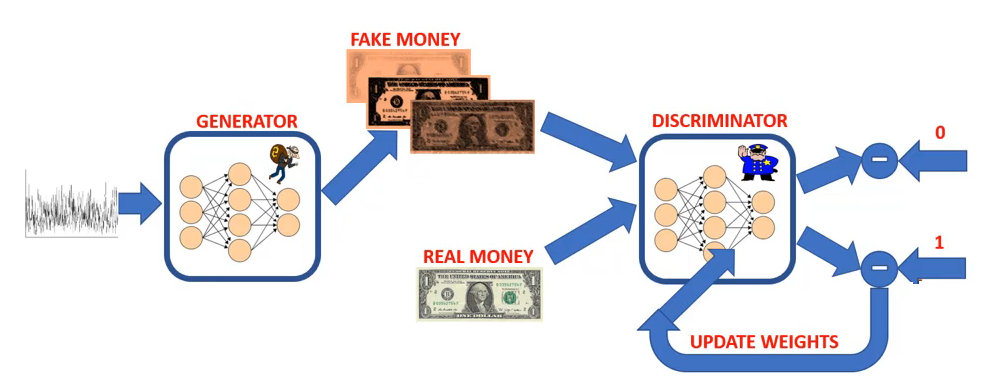
Steps of training GANs
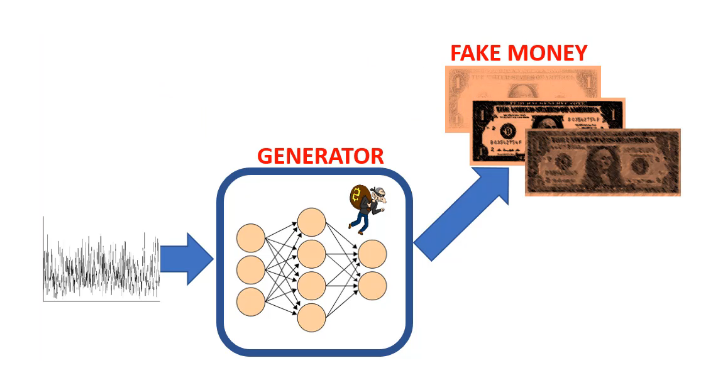
- Step 1.
The generator takes in random noise and generates fake images.
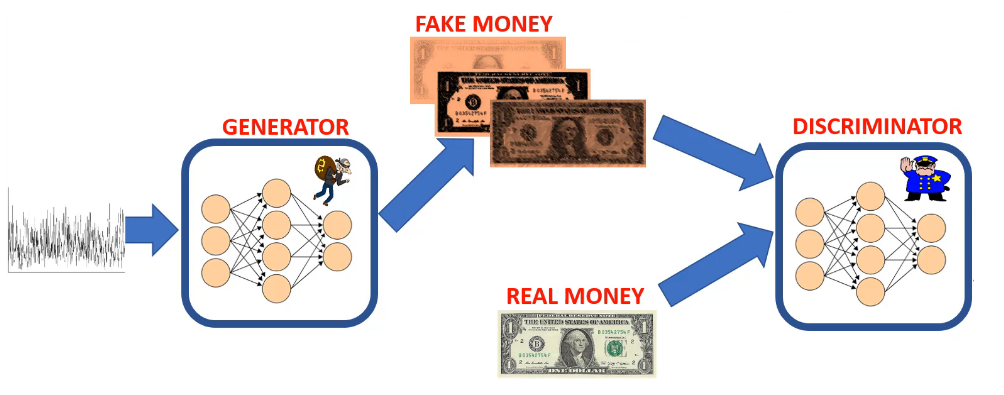
- Step 2.
Both fake and real images are fed to the discriminator network (feedforward path).
- Step 3.
The discriminator will generate predictions based on the input images (both real and fake images).
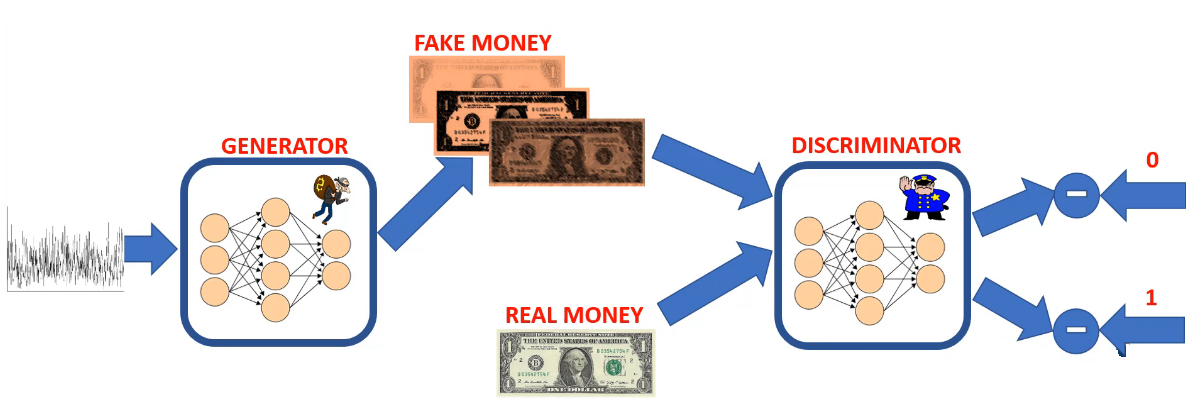
Step 4.
The predictions of discriminator are compared to the true labels to calculate the error.Step 5.
The error is backpropagated through the network to update the discriminator’s weights.
- Step 6.
The discriminator gives feedback to the generator on how far off the generator is from generating real images.
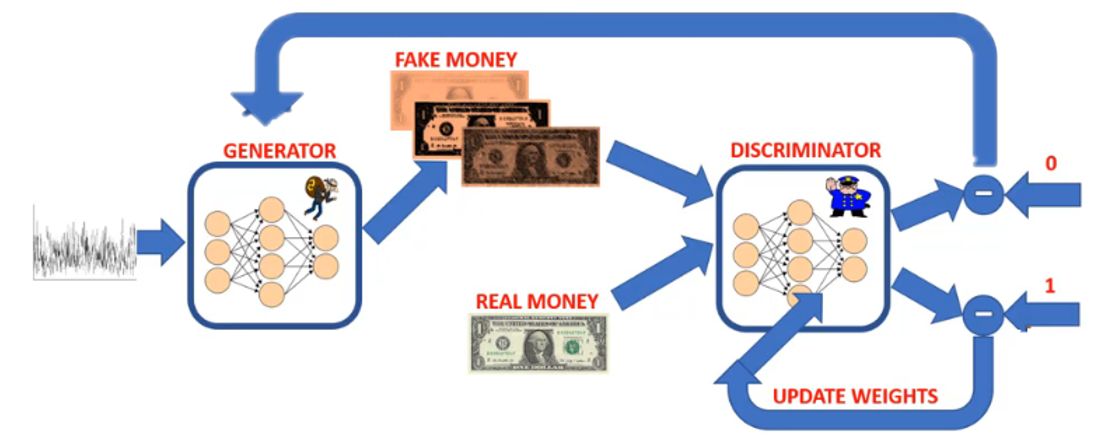
- Step 7.
The generator’s weights are updated while the discriminator’s weights are frozen.
Example
Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
from __future__ import absolute_import, division, print_function, unicode_literals
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
import tensorflow as tf
BUFFER_SIZE = len(train_images)
BATCH_SIZE = 256
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
# BUILD GENERATOR
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,))) # 7*7*256 = 12544
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU()) # LeakyReLu: Do not set any number negative
model.add(layers.Reshape((7, 7, 256)))
# Because we used "same" padding and stride = 1, the output is the same size as input 7 x 7 but with 128 filters instead
# Resulting in 7 x 7 x 128
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# Because we used "same" padding and stride = 2, the output is double the size of the input 14 x 14 but with 64 filters instead
# Resulting in 14 x 14 x 64
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# Because we used "same" padding and stride = 2, the output is double the size of the input 28 x 28 but with 1 filter instead
# Resulting in 28 x 28 x 1
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
model.summary()
return model
# BUILD THE DISCRIMINATOR
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
model.summary()
return model
# DEFINE THE LOSS FUNCTIONS FOR BOTH NETWORKS
# computes the 'loss' which simply the difference between the model predictions and the true label
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
# The discriminator loss indicates how well the discriminator is able to distinguish real and fake images.
# It compares the discriminator's predictions on real images to an array of 1s,
# and the discriminator's predictions on fake (generated) images to an array of 0s.
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss # sum up both losses
return total_loss
# The generator's loss quantifies how well it was able to trick the discriminator.
# if the generator is performing well, the discriminator will classify the fake images as real (or 1).
# Here, we will compare the discriminators decisions on the generated images to an array of 1s.
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
# TRAIN THE MODEL
EPOCHS = 100
noise_dim = 100
num_examples_to_generate = 16
seed = tf.random.normal([num_examples_to_generate, noise_dim])
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True) # step 1. call the generator and feed in the noise seed
real_output = discriminator(images, training=True) # step 2. pass the fake and real ones to discriminator to perform classification
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output) # step 3. Calculate the loss for both the generator and discriminator
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables) # step 4. calculate the gradient of the losses
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables)) # step 5. Apply the optimizers and update weights
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as we go
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
def generate_and_save_images(model, epoch, test_input):
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4,4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
train(train_dataset, EPOCHS)
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(EPOCHS)
Result
