What is Restricted Boltzmann Machine (RBM)
RBM is devised to overcome the limitations of computation. The reason for the increased amount of computation is that there are too many nodes to calculate when the Boltzmann machine is applied in practice. So, for simplicity, RBM is devised.
The simple structure of RBM:
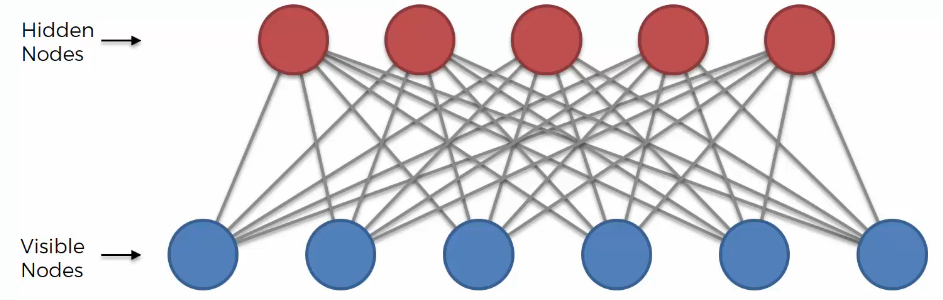
The Boltzmann machine and RBM are mostly similar, but there are no connections between hidden nodes. Also, there are no connections between visible nodes.
How is RBM used?
Let’s assume we are making a movie recommendation system.
During training of the RBM, we can help the Boltzmann machine represent our system by feeding it data through a process called contrast divergence. Through this process, RBM understands how to allocate hidden nodes to specific features. This process is similar to CNN.
For example, there are review scores about Moive 1 to 6.
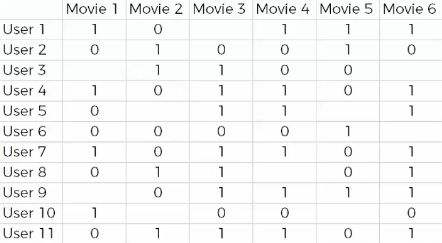
If the user liked the movie, the score will be 1. If not, the score will be 0. There is also a blank, meaning that the user did not see that movie. By feeding this data into the limiting Boltzmann machine, the machine understands our system better, and as it adjusts itself, it can better represent our system and better understand and express the connectivity within it, because users have biases and tastes, and that’s reflected in this data.
Let’s take a simple example.
Movie 3, 4, and 6 generally have similar ratings. Most, but not always, user who liked Movie 3 and 4 also liked Movie 6, and user who liked Movie 6 and 4 or 6 and 3 probably rated Movie 4 or 3. If the user liked 6 and 3, user will like 4, and if the user didn’t like Movie 3 and 4, the user will hate 6 too.
From this similarity, we can extract features that movies have in common.
Now, let’s see the steps that happen in RBM.
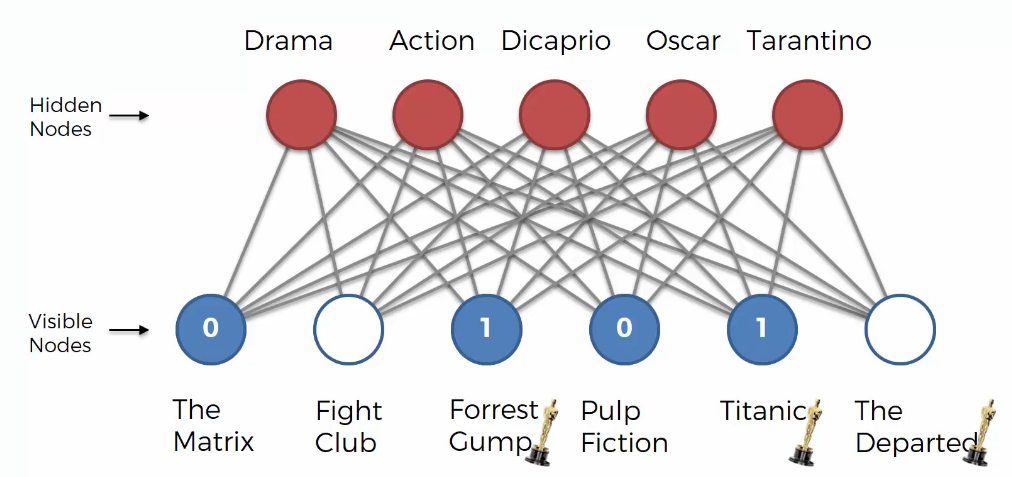
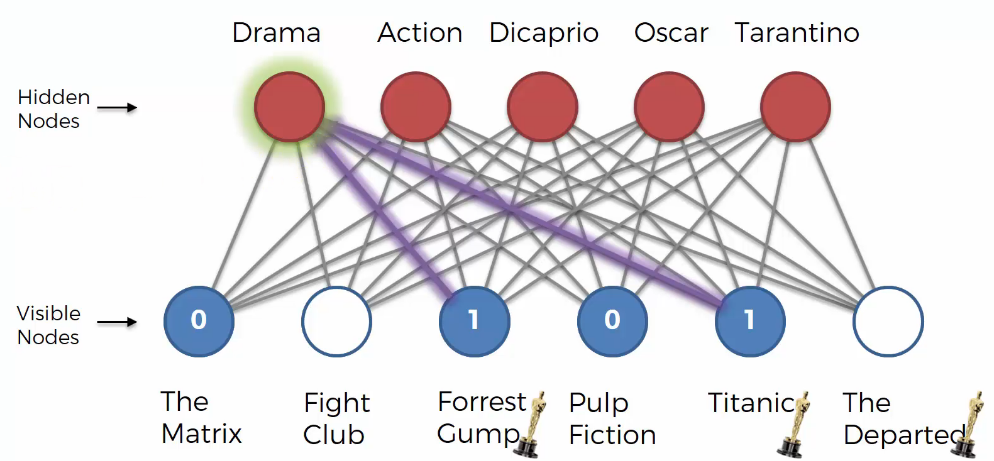
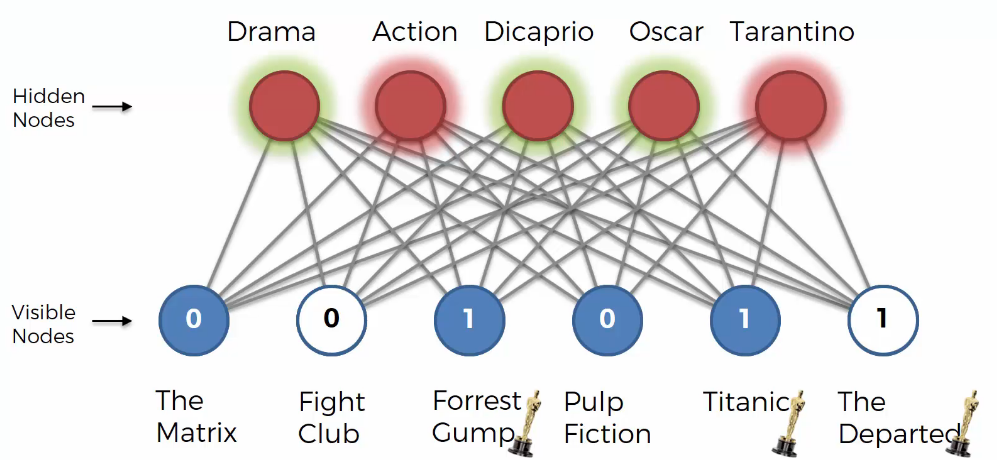
We can guess the user likes “Drama” because the user likes “Forrest Gump” and “Titanic”. Based on that, “Drama” node is activated.
We can guess the user doesn’t like “Action” because the user likes “The Matrix” and “Pulp Fiction”. Based on that, “Action” node is deactivated.
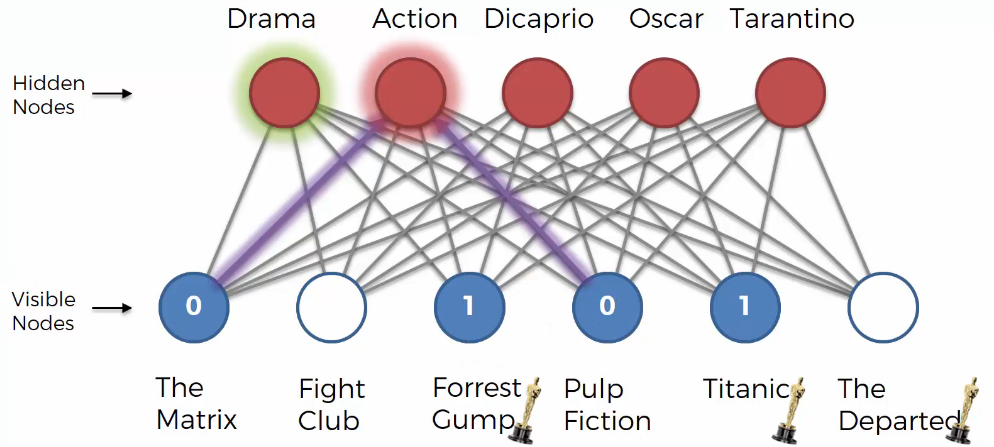
We can guess the user likes “Dicaprio” because the user likes “Titanic”. Based on that, “Dicaprio” node is activated.
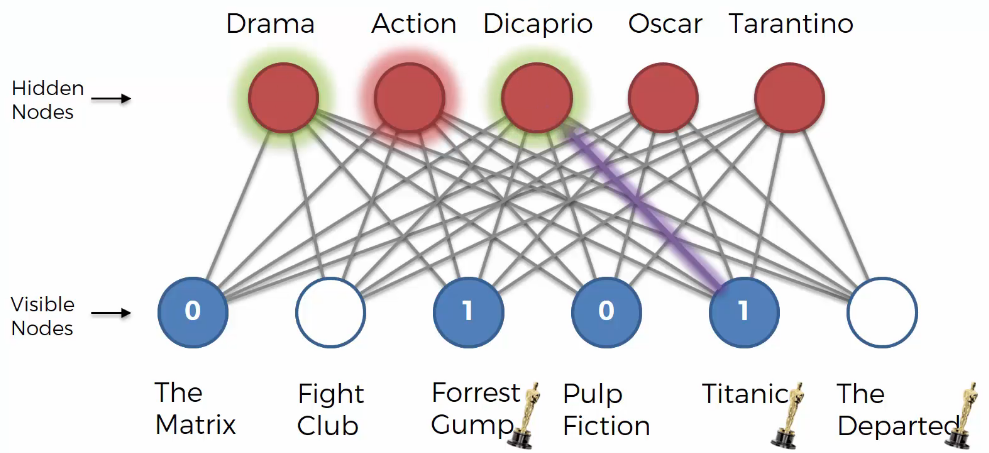
We can guess the user likes “Oscar” because the user likes “Forrest Gump” amd “Titanic”. Based on that, “Oscar” node is activated.
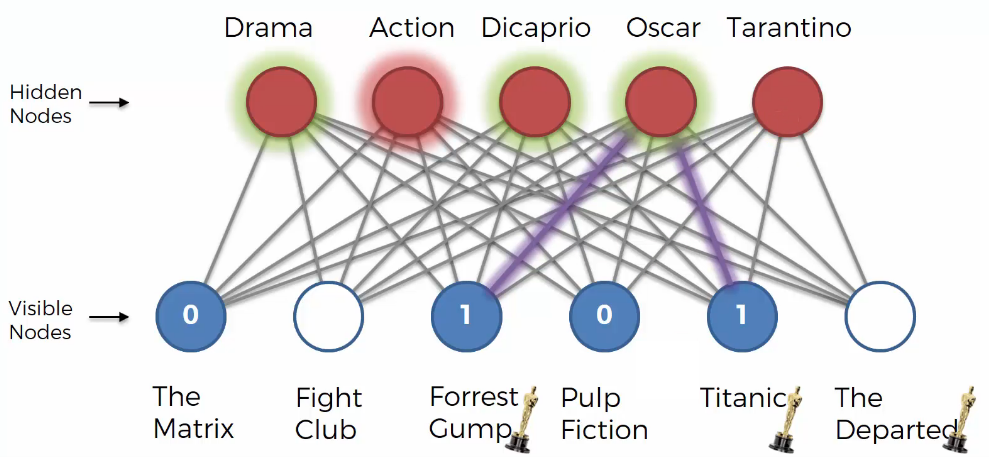
We can guess the user likes “Dicaprio” because the user doesn’t like “Pulp Fiction”. Based on that, “Tarantino” node is deactivated.
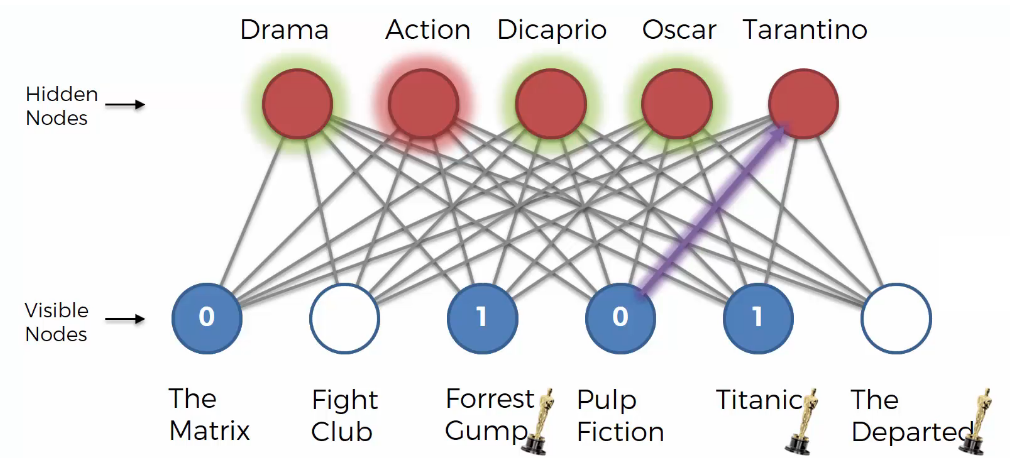
The above process is called a pass, and it is the first pass. All visible nodes are connected to hidden nodes and we knows which hidden nodes are activated.Next, the backward pass occurs. The RBM will reconstruct the inputs.
During testing, there is no process of adjusting weights. That is, the weights are never modified basically. It just gets a vector as input and tries to fill in the empty values in the vector. In the image above, RBM fills in “Fight Club” and “The Departed”.
Then, let’s see which features does “Fight Club” and “The Departed” have.
| Movies | Drama | Action | Dicaprio | Oscar | Tarantino |
|---|---|---|---|---|---|
| Fight Club | X | O | X | X | X |
| The Departed | O | O | O | O | X |
according to the table above, we can get predicted values of “Fight Club” and “The Departed”.
Example
Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
from torch.autograd import Variable
# Getting the number of users and movies
nb_users = max(max(training_set[:, 0]), max(test_set[:, 0]))
nb_movies = max(max(training_set[:, 1]), max(test_set[:, 1]))
# Converting the data into an array with users in lines and movies in columns
def convert(data):
new_data = []
for id_users in range(1, nb_users + 1):
"""id_movies : A list containing the data of movies rated by the ith user
id_ratings: A list of rating data rated by the ith user"""
id_movies = data[:, 1][data[:, 0] == id_users]
id_ratings = data[:, 2][data[:, 0] == id_users]
# Fill 0 for unrated movies
ratings = np.zeros(nb_movies)
ratings[id_movies - 1] = id_ratings
new_data.append(list(ratings))
return new_data
training_set = convert(training_set)
test_set = convert(test_set)
"""Converting the ratings into binary ratings 1(Liked) or 0 (Not LIked)
Why convert to 0 and 1: To provide consistent data for RBMs to calculate unrated ratings.
The reason for converting 0 in the dataset to -1: because it is an unevaluated item
The reason for dividing ratings 1 and 2: torch tensor does not recognize or"""
training_set[training_set == 0] = -1
training_set[training_set == 1] = 0
training_set[training_set == 1] = 0
training_set[training_set >= 3] = 0
test_set[test_set == 0] = -1
test_set[test_set == 1] = 0
test_set[test_set == 2] = 0
test_set[test_set >= 3] = 0
# Creating the architecture of the Neural Network
class RBM():
"""nv : visible node
nh : hidden node"""
def __init__(self, nv, nh):
# Randomly initialize weights
self.W = torch.randn(nh, nv)
# Bias initialize
"""1 : fake dimension for batch
nh : bias
Since the torch accepts a 2-dimensional vector, we create a fakedimension."""
self.a = torch.randn(1, nh)
self.b = torch.randn(1, nv)
"""A function that calculates the probability that a hidden node is activated by a visible node
x : Probability of hidden null"""
def sample_h(self, x):
wx = torch.mm(x, self.W.t())
activation = wx + self.a.expand_as(wx)
p_h_given_v = torch.sigmoid(activation)
return p_h_given_v, torch.bernoulli(p_h_given_v)
# A function that calculates the probability that a visible node is activated by a hidden node
def sample_v(self, y):
wy = torch.mm(y, self.W)
activation = wy + self.b.expand_as(wy)
p_v_given_h = torch.sigmoid(activation)
return p_v_given_h, torch.bernoulli(p_v_given_h)
"""v0: input vector (user's evaluation)
VK: visible node created after k sampling
ph: Probability of the first hidden node
phk: probability after k sampling"""
def train(self, v0, vk, ph0, phk):
self.W += (torch.mm(v0.t(), ph0) - torch.mm(vk.t(), phk)).t()
self.b += torch.sum((v0 - vk), 0)
self.a += torch.sum((ph0 - phk), 0)
nv = len(training_set[0])
nh = 100 # Tunable
# batch_size: update after observation as much as the batch size
batch_size = 100 #Tunable
rbm = RBM(nv, nh)
# Training the RBM
nb_epoch = 10
for epoch in range(1, nb_epoch+1):
train_loss = 0
s = 0.
# After observing users as much as the batch size, the weights are updated.
for id_user in range(0, nb_users - batch_size, batch_size):
"""vk : visual node to be created
v0 : first visual node"""
vk = training_set[id_user:id_user+batch_size]
v0 = training_set[id_user:id_user+batch_size]
ph0,_ = rbm.sample_h(v0)
# Gibbs sampling
for k in range(10):
_,hk = rbm.sample_h(vk)
_,vk = rbm.sample_v(hk)
vk[v0<0] = v0[v0<0]
phk,_ = rbm.sample_h(vk)
rbm.train(v0, vk, ph0, phk)
train_loss += torch.mean(torch.abs(v0[v0>=0] - vk[v0>=0]))
s += 1.
print('epoch:', epoch, 'loss:', (train_loss/s))
# Testing the RBM
# Using the Markov chain Monte Carlo (MCMC) technique
test_loss = 0
s = 0.
for id_user in range(nb_users):
# The reason why v is not changed to test_set is that it can be used to activate RBM's hidden neurons.
v = training_set[id_user:id_user+1]
vt = test_set[id_user:id_user+1]
if len(vt[vt>=0]) > 0:
_,h = rbm.sample_h(v)
_,v = rbm.sample_v(h)
test_loss += torch.mean(torch.abs(vt[vt>=0] - v[vt>=0]))
s += 1.
print('test loss:', (test_loss/s))
Exmaple
1
test loss: 0.24292576133202015